

Traditional databases have been useful in storing, retrieving, and managing data in the data management field for decades. Traditional databases, however, are no longer adequate to meet the needs of modern enterprises due to the proliferation and complexity of data. As a solution to that, Vector databases come into play here.
Vector databases are a new form of database technology that allows for quicker processing and enhanced analytics than traditional databases. In this post, we will discuss the fundamentals of vector databases in depth, the advantages of using them, how they differ from traditional databases, and popular use cases. Keep scrolling through to learn all about it.
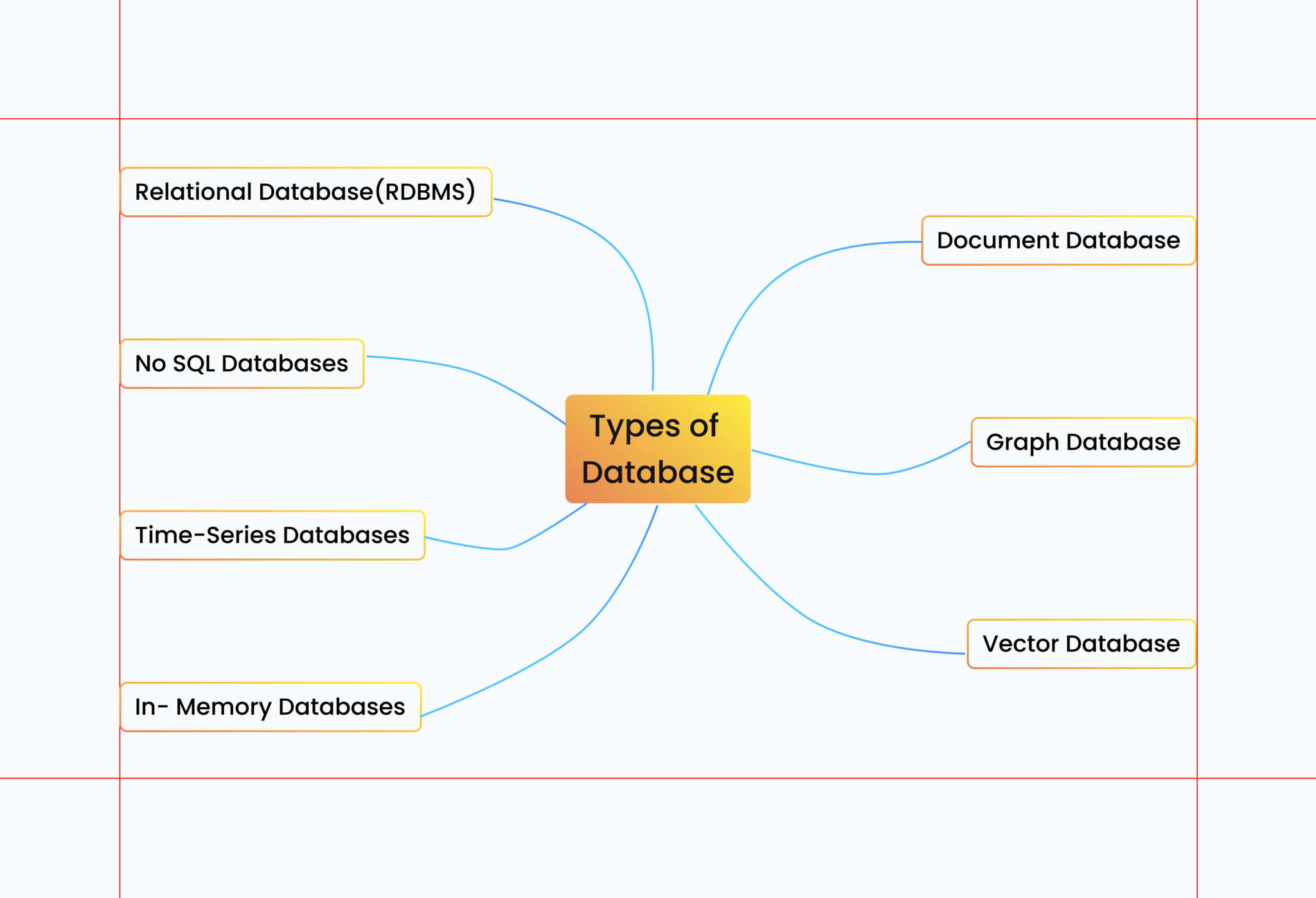
What are Vector databases?
Before anything else, it’s important to understand Vector databases. A vector database is a database created to work with large volumes of complex data. They differ from traditional databases and are better. Vector databases, as opposed to regular databases, store data in vector form. Vectors are mathematical data formats that enable quick processing and querying. Vector databases, in essence, are meant to manage high-dimensional data, which is data with numerous qualities or features.

Vectors are mathematical data formats
Vector databases store data as vectors. Vectors are mathematical data formats that enable quick processing and querying. Each data point in a vector database is represented by a vector that describes its properties or features. These vectors may be utilized for a variety of tasks such as distance computations, grouping, and searching. Consider a dataset of a clothing store’s consumer preferences.
Each consumer may be represented as a vector with variables such as age, gender, clothing size, favorite color, and favorite style. This vector is useful when you want to find similar customers who may want to purchase similar products. It can also be used to cluster customers into groups according to their product preferences.
How do Vector databases operate?
As you know, with traditional databases, you often look for rows in the database where the valuation fits our query accurately. A similarity measure is used in vector databases to locate the vector that is most similar to our query. A similarity measure can be used in vector databases to locate the vector that is most similar to your query.
A vector database makes use of several strategies, all of which contribute to the ANN (Approximate Nearest Neighbor) search. Such algorithms improve search results by using quantization, graph-based, or hashing search. The algorithms get combined into a pipeline, allowing accurate and fast searches of vector neighbors.
Index: Vectors are indexed in the vector database with the use of an algorithm like LSH or PQ. This stage converts the vectors into a data structure that allows for speedier searching.
Query: To find the nearest neighbors (using the index’s similarity measure), the vector database runs comparisons of indexed vectors in the dataset to the indexed query vector.
Post-processing: At this stage, it refines the results of the original query by sorting, filtering, and combining the searched vectors.
Differences between Vector databases and traditional databases
As we mentioned earlier, traditional databases and vector databases have differences. The primary distinctions between vector and classic databases are their data structures and indexing methodologies. Traditional databases store information in tabular format, but vector databases store information in vector format.
Row-based and column-based indexing
Row-based indexing is used in traditional databases, but column-based indexing is used in vector databases. Row-based indexing is useful for finding a group of rows that meet certain criteria, but it is inefficient for retrieving data based on similarities.
In vector databases, column-based indexing is more efficient for obtaining data based on similarities and dissimilarities. Another significant distinction between vector and classic databases is their capacity to manage high-dimensional data. Traditional databases may struggle with high-dimensional data due to the sheer quantity of properties or features. However, Vector databases can work with high-dimensional data efficiently.
Overall, vector databases are an effective tool for dealing with complicated and multidimensional data. They are well-suited for applications such as recommendation systems, picture and video analysis, and natural language processing due to their ability to store data in vector form and employ efficient indexing and querying methods.
What are the pros of Vector databases?
Vector databases have various advantages, and they have grown in popularity in recent years because of their better efficiency and speed, scalability, and greater data analytics and visualization capabilities. Vector databases are a subset of regular databases that are meant to manage complicated data more effectively.
They employ high-speed indexing and querying methods, which allow for speedier data processing and retrieval. This implies that queries may be processed faster, resulting in enhanced performance and speed.
With Vector databases’ incredible scalability and flexibility, they are great at handling enormous volumes of data because they can be readily deployed across several nodes and tuned for certain tasks. Vector databases are also highly versatile, with the ability to handle a diverse range of data formats such as photos, text, and videos.
1. Better performance
Vector databases are designed for parallel processing, so they can benefit from modern multi-core CPUs and distributed computing systems for even quicker processing. As a result, they are perfect for managing enormous amounts of data and sophisticated queries. Vector databases also have the ability to handle high-dimensional data.
Traditional databases struggle with high-dimensional data, whereas vector databases are built to handle it better. They are capable of performing sophisticated calculations and operations on multidimensional data, such as grouping, classification, and anomaly detection.
2. Advanced data analytics and visualization
Vector databases are intended for advanced data analytics and visualization. They are capable of performing sophisticated calculations and operations on multidimensional data, such as grouping, classification, and anomaly detection. This enables firms to obtain insights from their data and make more educated decisions.
Vector databases can also be connected with popular data visualization tools like Tableau and Power BI to make data visualization and exploration easier. This can assist firms in identifying trends and patterns in their data and gaining a better understanding of their business operations. Overall, the benefits of using vector databases are obvious. They provide greater data analytics and visualization capabilities, as well as improved performance and speed.
In the future, vector databases are projected to grow in popularity as organizations produce ever-increasing amounts of data.
3. Flexibility and scalability of vector databases
Vector databases are highly scalable and adaptable. This makes them perfect for both big and small enterprises. They can be readily scaled up or down based on company needs, and they can be tuned for certain workloads. This means that organizations may use vector databases to handle massive amounts of data without experiencing performance problems. Vector databases are also extremely versatile, with the ability to accommodate a wide range of data formats.
They can work with unstructured data like text, photos, and videos as well as structured data like numbers and dates. As a result, they are perfect for enterprises that need to process a wide range of data types.
What are the most common use cases for Vector databases?
Vector databases are widely utilized in a variety of areas, including healthcare, finance, and e-commerce. They are gaining popularity as a result of their ability to handle complicated data types, such as spatial and high-dimensional data, and execute advanced operations on that data. Let’s look at the most prevalent use cases:
Use case 1: Machine learning and artificial intelligence
To train algorithms and generate predictions, machine learning and AI (artificial intelligence) require massive amounts of data. Because vector databases can manage high-dimensional data and conduct complicated operations on it, they are perfect for machine learning and AI applications. Vector databases, for example, can be used to store and analyze medical imaging data in order to build better diagnostic tools.
Vector databases can be used in healthcare to store and analyze patient data such as medical imaging, electronic health records, and genomic data. This data can be utilized to create individualized treatments, forecast disease outcomes, and discover novel drug targets. Vector databases are used in finance to store and analyze financial data such as stock prices, economic indicators, and news items. This data can be used to forecast market trends, spot investment opportunities, and manage risk.
Use case 2: GIS (Geographic Information Systems)
GIS is a system for collecting, storing, and analyzing geographic data. It’s incorporated into applications like disaster response, environmental management, urban planning, and Because vector databases can manage enormous volumes of spatial data and perform complex spatial analysis, they are perfect for GIS applications.
Vector databases, for example, can be used to store and analyze data from GPS sensors, satellite photography, and other sources of spatial data. Vector databases can be used in urban planning to store and evaluate data on population density, land use, and transit networks. This data can be utilized to make informed zoning, infrastructure development, and transit planning decisions.
Vector databases can be used in environmental management to store and analyze data on natural resources such as water and forests, as well as track changes over time. Vector databases can be used in disaster response to store and analyze data on the location and severity of natural catastrophes such as earthquakes and hurricanes, as well as to coordinate emergency response activities.
Use case 3: Real-time data processing
Real-time data processing necessitates quick and efficient data processing as it is generated. Because vector databases can manage high-volume data streams and execute real-time analysis on that data, they are suitable for real-time data processing. Vector databases, for example, can be used to store and analyze data from IoT sensors in order to monitor and control industrial operations.
This type of databases can be used in manufacturing to store and evaluate data on production processes such as temperature, pressure, and humidity. This data can be utilized to increase manufacturing efficiency, decrease waste, and enhance product quality. Vector databases can be used in transportation to store and evaluate data on traffic patterns, meteorological conditions, and vehicle performance. This information can be used to reduce fuel consumption, optimize route planning, and improve safety.
Overall, vector databases are an effective tool for maintaining and analyzing complex data types across a wide range of sectors. As the volume of data generated grows, so will the demand for effective and scalable data storage and processing solutions.
What are the most popular Vector database solutions?
There are various common vector database systems available, each with its own pros and cons. PostGIS, Elasticsearch, and ArangoDB are some of the most popular systems.
1. PostGIS
PostGIS is a PostgreSQL-based open-source vector database. It is intended for geographical data handling and supports geographic information systems (GIS) applications. PostGIS is widely used in the geospatial sector and has a large and active user and developer community.
2. Elasticsearch
Elasticsearch is a Lucene-based distributed search engine designed to be used for real-time data processing and full-text search. Through its interaction with the Apache Arrow library, Elasticsearch supports vector data. Elasticsearch is frequently utilized in enterprise and e-commerce applications.
3. Pinecone
The Pinecone vector database simplifies the development of high-performance vector search applications. Developer-friendly, completely managed, and easily expandable without the need for infrastructure
4. ArangoDB
ArangoDB is a multi-model database that can store data in graph, document, and key-value formats. Through its interaction with the Numpy library, it supports vector data. ArangoDB is a high-performance and scalable database that is frequently utilized in web and mobile applications.
Wrapping up
Vector databases are a new technology that outperforms standard databases in terms of performance, scalability, and adaptability. They are perfect for dealing with complex data as well as advanced data analytics and visualization. GIS (Geographic information systems), machine learning, AI, and real-time data processing are just a few of the applications for vector databases.
As we discussed, a lot of Vector database systems are currently available. We can predict that the demand for vector databases is likely to rise over time as data volumes and complexity continue to rise. Follow our blog for similar posts.